Blank page problem
As mentioned above, one of the advantages of the simulation is that it avoids the blank page problem for both a user and a large language model by providing creative fuel. Even experienced writers can sometimes feel overwhelmed when asked to come up with a title or story idea without any prior incubation of related material. The same could be said for LLMs. The simulation provides context and data points before starting the creative process.
Who is driving the story?
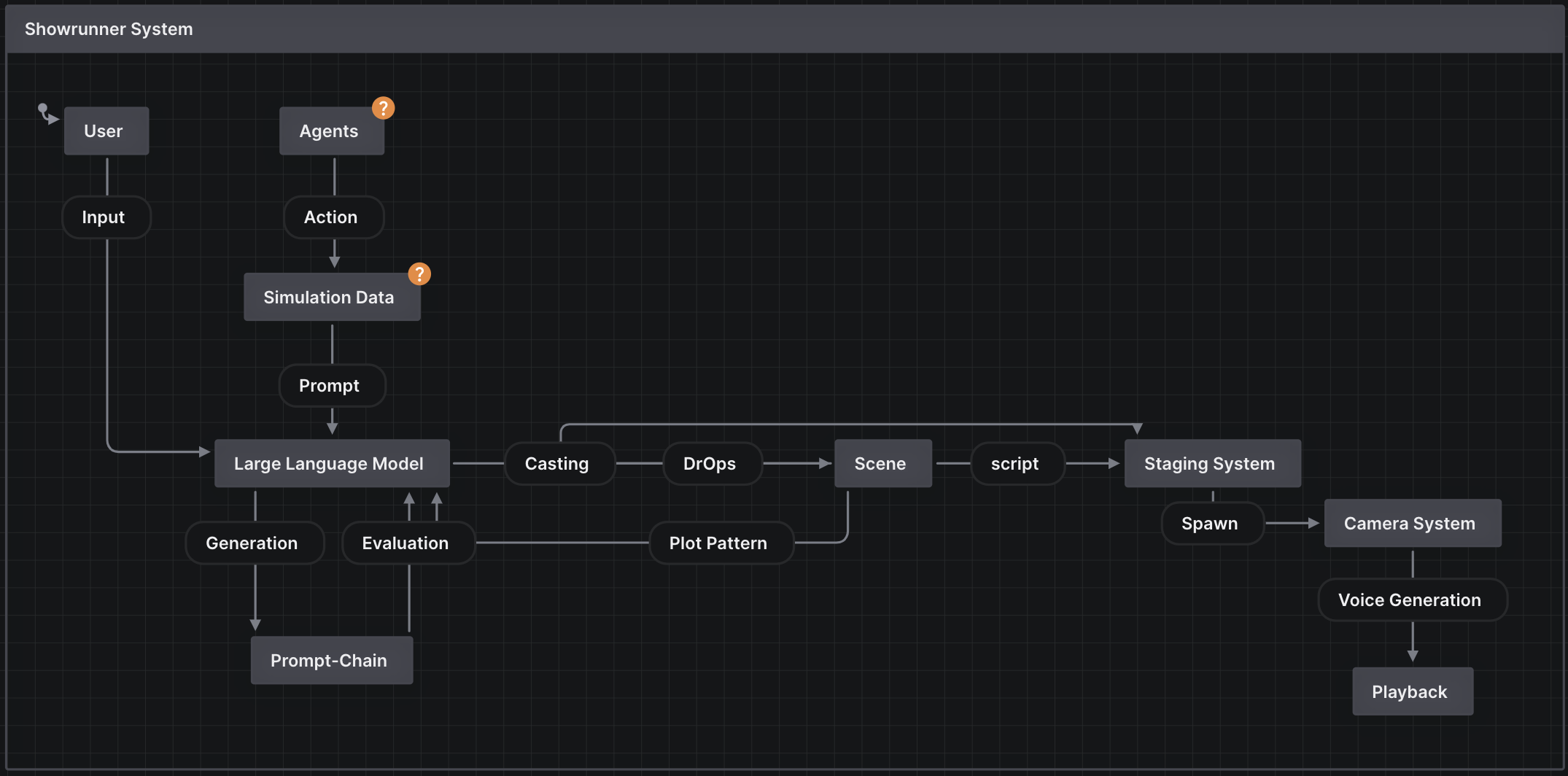
The story generation process in this proposal is a shared responsibility between the simulation, the user, and GPT-4. Each has strengths and weaknesses and a unique role to play depending on how much we want to involve them in the overall creative process. Their contributions can have different weights. While the simulation usually provides the foundational IP-based context, character histories, emotions, events, and localities that seed the initial creative process. The user introduces their intentionality, exerts behavioral control over the agents and provides the initial prompts that kick off the generative process. The user also serves as the final discriminator, evaluating the generated story content at the end of the process. GPT-4, on the other hand, serves as the main generative engine, creating and extrapolating the scenes and dialogue based on the prompts it receives from both the user and the simulation. It should be a symbiotic process where the strengths of each participant contribute to a coherent, engaging story.
SHOW-1 and Intentionality
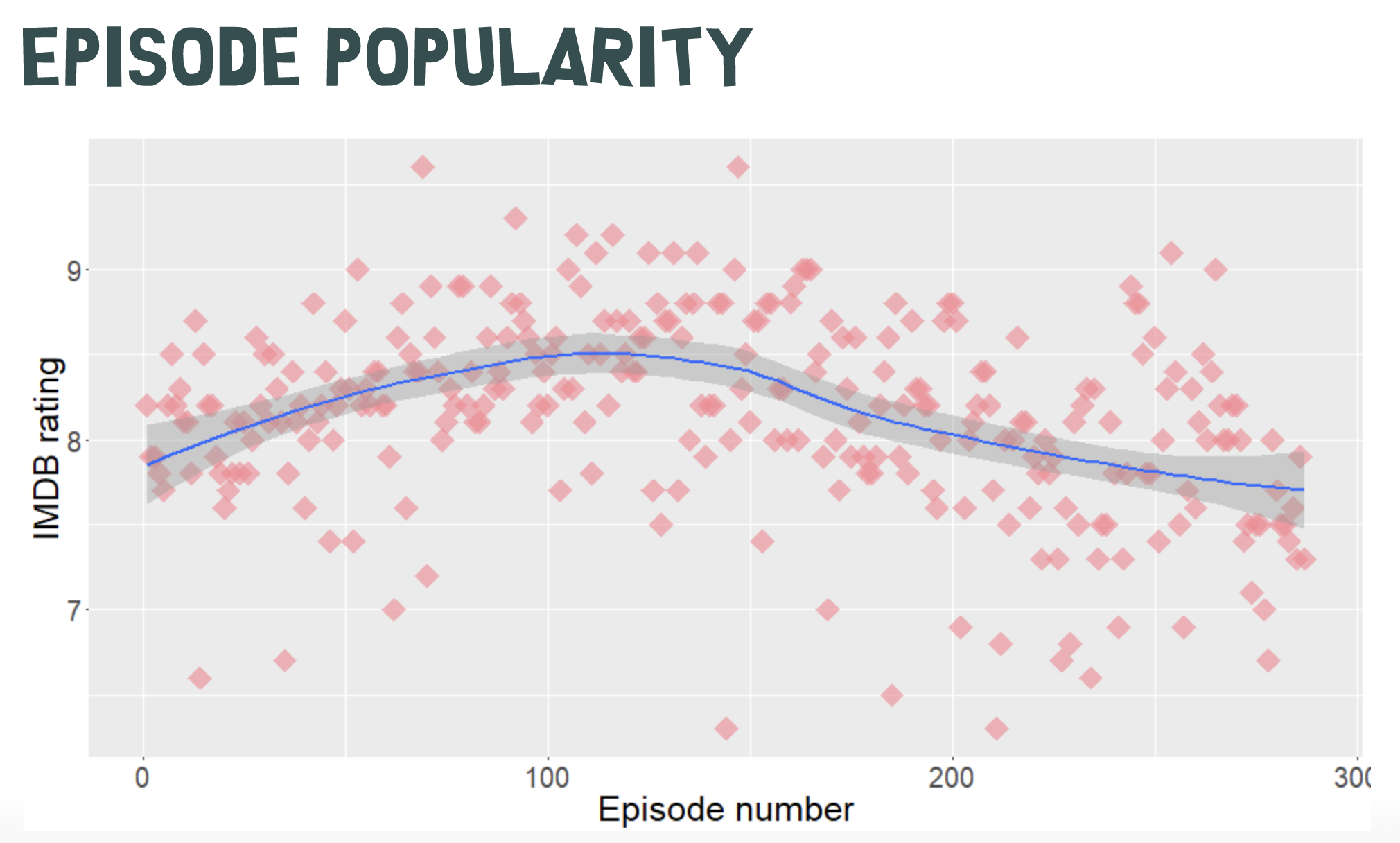
The formular (creative characteristics) and format (technical characteristics) of a show are often a function of real-world limitations and production processes. They usually don't change, even over the course of many seasons (South Park currently has 26 seasons and 325 episodes)
A single dramatic fingerprint of a show, which could be used to train the proposed SHOW-1 model, can be regarded as a highly variable template or "formula" for a procedural generator that produces South Park-like episodes.
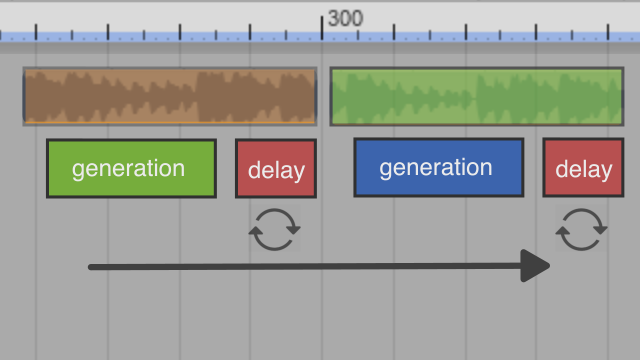
To train a model such as SHOW-1 we need to gather a sufficient amount of data points in relation to each other that characterize a show. A TV show does not just come into existence and is made up of the final dialogue lines and set descriptions as seen by the audience. Existing datasets on which current LLM's are trained on only consist of the final screenplay which has the cast, dialogue lines and sometimes a short scene header. A lot of information is missing, such as timing, emotional states, themes, contexts discussed in the writer's room and detailed directorial notes to give a few examples. The development and refinement of characters is also part of this on-going process. Fictional characters have personalities, backstories and daily routines which help authors to sculpt not only scenes but the arcs of whole seasons. Even during a show characters keep evolving based on audience feedback or changes in creative direction. With the Simulation, we can gather data continuously from both the user's input and the simulated agents. Over time, as episodes are created, refined and rated by the user we can start to train a show specific model and deploy it in the future as a checkpoint which allows the user to continue to refine and iterate on either their own original show or alternatively push an already existing show such as south park into directions previously not conceived by the original show runners and IP holders. To illustrate this, we imagine a user generating multiple south park episodes in which Cartman, one of the main characters and known for his hot headedness, slowly changes to be shy and naive while the life of other characters such as Butters could be tuned to follow a much more dominant and aggressive path. Over time, this feedback loop of interacting with and fine-tuning the SHOW-1 model could lead to new interpretations of existing shows but more excitingly to new original shows based on the user's intention. One of the challenges in order to make this feedback loop engaging and satisfying is the frequency at which a model can be trained. A model which is fed by real-time simulation data and user input should not feel static or require expensive resources to adapt. Otherwise the output it generates can feel static and unresponsive as well.
When a generative system is not limited in its ability to swiftly produce high amounts of content and there is no limit for the user to consume such content immediately and potentially simultaneously, the 10,000 Bowls of Oatmeal problem can become an issue. Everything starts to look and feel the same or even worse, the user starts to recognize a pattern which in turn reduces their engagement as they expect newly generated episodes to be like the ones before it, without any surprises.
This is quite different from a predictable plot which in combination with the above mentioned "positive hallucinations" or happy accidents of a complex generative system can be a good thing. Surprising the user by balancing and changing the phases of certainty vs. uncertainty helps to increase their overall engagement. If they would not expect or predict anything, they could also not get pleasantly surprised.
With our work we aim for perceptual uniqueness. The "oatmeal" problem of procedural generators would be mitigated by making use of an on-going simulation (a hidden generator) and the long-form content of 22 min episodes which should only get generated every 3h. In this way the user generally does not consume a high quantity of content simultaneously or in a very short amount of time. This artificial scarcity, natural game play limits and simulation time help.
Another factor that keeps audiences engaged while watching a show and what makes episodes unique is intentionality from the authors. A satirical moral premise, twisted social commentary, recent world events or cameos by celebrities are major elements for South Park. Other show types, for example sitcoms, usually progress mainly through changes in relationship (some of which are never fulfilled), keeping the audience hooked despite following the same format and formula.
Intentionality from the user to generate a high-quality episode is another area of internal research. Even users without a background in dramatic writing should be able to come up with stories, themes or major dramatic questions they want to see played out within the simulation.
To support this, the showrunner system could guide the user by sharing its own creative thought process and make encouraging suggestions or prompting the user by asking the right questions. A sort of reversed prompt engineering where the user is answering questions.
One of the remaining unanswered questions in the context of intentionality is how much entertainment value (or overall creative value) is directly attributed to the creative personas of living authors and directors. Big names usually drive ticket sales but the creative credit the audience gives to the work while consuming it seems different.
Watching a Disney movie certainly carries with it a sense of creative quality, regardless of famous voice actors, as a result of brand attachment and its history.
AI generated content is generally perceived as lower quality and the fact that it can get generated in abundance further decreases its value. How much this perception would change if Disney were to openly pride themselves on having produced a fully AI generated movie is hard to say. What if Steven Spielberg, single handedly generated an AI movie? Our assumption is that the perceived value of AI generated content would certainly increase.
A new interesting approach to replicate this could be the embodiment of creative AI models such as SHOW-1 to allow them to build a persona outside their simulated world and build relationships via social media or real world events with their audience. As long as an AI model is perceived as a black box and does not share their creative process and reasoning in a human and accessible way, as is the case for living writers and directors, it's unlikely to get credit with real creative values. However, for now this is a more philosophical question in the context of AGI.